昨天我們理解了比賽的任務、評分方式,並完成資料解壓與前處理。今天,我們要進一步了解資料的分布與特徵,這一步叫做探索式資料分析(Exploratory Data Analysis, EDA)。
首先我們用 describe() 來快速檢查數值欄位的統計資訊:
display(train.describe())
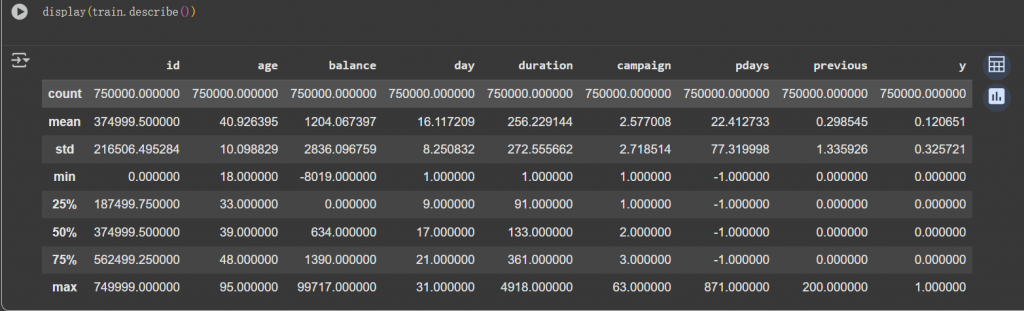
| 欄位 | 觀察 |
|---|---|
| age | 年齡範圍 18–95 歲,平均 40 歲,中位數 39 歲 |
| balance | 有負值(最低 -8019),代表欠款或透支狀態,中位數是 634 |
| day | 分布在 1–31,一個月就是1-31天合理 |
| duration | 平均通話 256 秒,中位數 133 秒,但最大值到 4918 秒 |
| campaign | 通常聯絡次數 1–3 次,最大值 63 次,可能是極端值,需要注意 |
| pdays | pdays 在這個資料集中指的是距離客戶上一次被聯絡的天數,如果 pdays = -1,表示這個客戶之前從未被聯絡過。pdays = 30 → 上次聯絡是 30 天前,以此類推 |
| previous | 大部分都是 0(沒有先前行銷紀錄) |
| y | 只有 12% 的客戶有申請定存,是一個明顯不平衡的分類問題 |
接著我們把圖畫出來看看數值的分布
import matplotlib.pyplot as plt
train.hist(figsize=(15, 10))
plt.tight_layout()
plt.show()
透過這些直方圖,我們可以發現數值是否集中在某一區間,或是極端值很多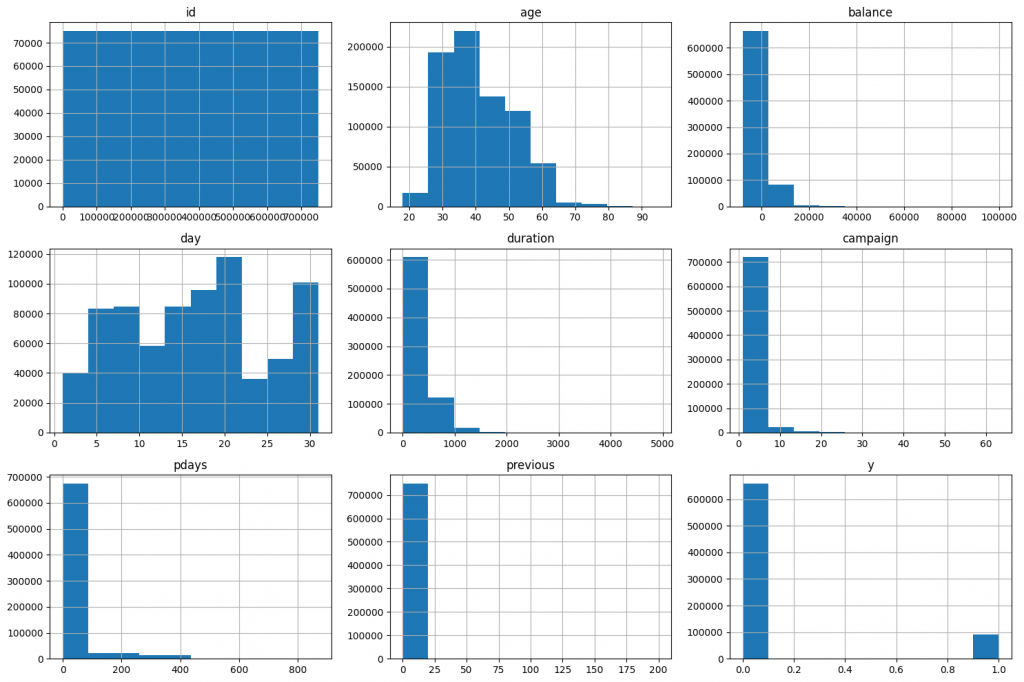
接著檢查類別欄位出現次數,確認是否有明顯不平衡,首先會先把這一欄(例如:年齡)裡每一種不同的值(18-95歲)各自出現的次數去做計算,接下來用normalize=True算成比例(出現次數 ÷ 總筆數),然後把<5% 歸類到非常不平衡,<10% 歸類到可能不平衡。
categorical_cols = train.select_dtypes(include=['object', 'category']).columns
for col in categorical_cols:
print(f"=== Column: {col} ===")
counts = train[col].value_counts()
ratios = train[col].value_counts(normalize=True)
for category, count in counts.items():
ratio = ratios[category]
flag = ""
if ratio < 0.05:
flag = "<5% (非常不平衡)"
elif ratio < 0.10:
flag = "<10% (可能不平衡)"
print(f"{category}: {count} ({ratio:.2%}) {flag}")
print("-" * 40)
接下來我們要特別觀察要預測的目標欄位,在這次的競賽中目標欄位是y,(內容通常是 "yes" 或 "no"或是"1"或"0"),代表客戶是否有定期存款(term deposit),也就是說,我們需要建立一個模型,根據客戶的特徵(年齡、工作、婚姻、貸款狀態、通話紀錄…),去預測他們最終到底會不會去銀行定期存款。
print(train['y'].value_counts(normalize=True))
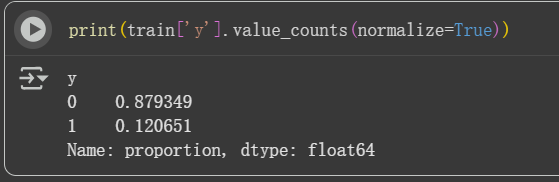
到這邊你會發現,沒有定期存款的大約是0.88,有定期存款的是0.12,這是一個類別不平衡的現象,我們需要處理它。而你可能會好奇,可能會覺得它就是我們要預測的最終答案啦,為什麼即使這樣,還需要在訓練時針對目標(target)去處理不平衡問題呢?
首先我們可以想成:如果模型什麼都不學,只要永遠預測 no,就會得到一個準確率 = 88%「準確度高」的模型(因為 88% 的人真的說 no),但這真的是一個「好」模型嗎?
模型會完全找不到任何會說 yes 的人! 很顯然這樣的模型不會是一個好模型,這個模型可以說是完全沒有用。為什麼沒有用呢?因為在我們今天的題目,對銀行來說,要找出可能會答應定期存款的人(yes)才有價值,所以如果模型只會預測 no,就浪費了行銷機會。
在做特徵工程的時候,我們常常要先問自己一個問題:
「哪些特徵真的跟我要預測的東西有關?」
因為如果把一堆沒用的特徵丟進去,模型可能會學到一些奇怪的規則,最後不但沒有比較好,還可能更差。
所以對於類別型變數,我們可以用 groupby 來計算每個類別中,目標變數是「有定期存款」(y=1)的比例。這個比例就叫做轉換率(Conversion Rate)。舉個例子:如果職業欄位裡有 200 個「上班族」,其中有 60 個人最後成功購買,那上班族的轉換率就是 60 ÷ 200 = 30%。這個數字告訴我們,上班族比其他類別更容易被轉換成「買單的客戶」。
用這種方法,我們就能觀察哪些特徵跟目標變數有關,像是不同的職業、婚姻狀態、教育程度,會不會對「成功行銷」的機率有影響,而這些特徵就是我們後面建模的重要線索。
import pandas as pd
import matplotlib.pyplot as plt
# 取得所有類別型欄位
categorical_cols = train.select_dtypes(include=['object', 'category']).columns
for col in categorical_cols:
# 計算每個類別中 y=1 的比例(轉換率)
crosstab = pd.crosstab(train[col], train['y'], normalize='index')
# 取出 y=1 的比例並排序
yes_rate = crosstab.get(1, pd.Series(dtype=float)).sort_values(ascending=False)
print(f"=== {col} ===")
print(yes_rate)
print("-" * 40)
# 畫出長條圖
yes_rate.plot(
kind='bar',
title=f"{col} vs Conversion Rate (Yes)",
ylabel="Conversion Rate",
xlabel=col,
)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
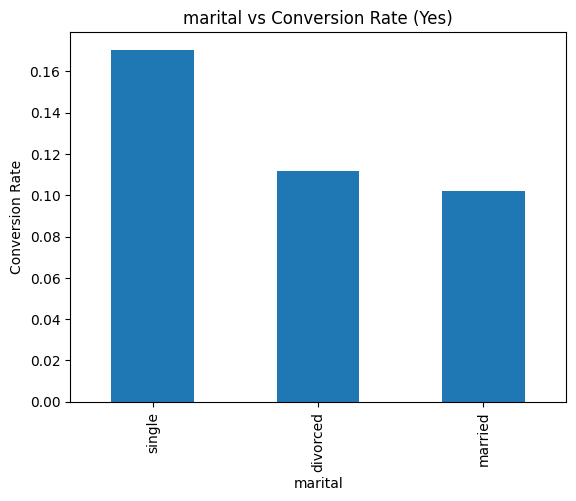
不同婚姻狀態對定期存款的影響。可以看到單身族群的轉換率明顯比已婚、離婚都高,這或許說明單身的人對金融產品更有興趣?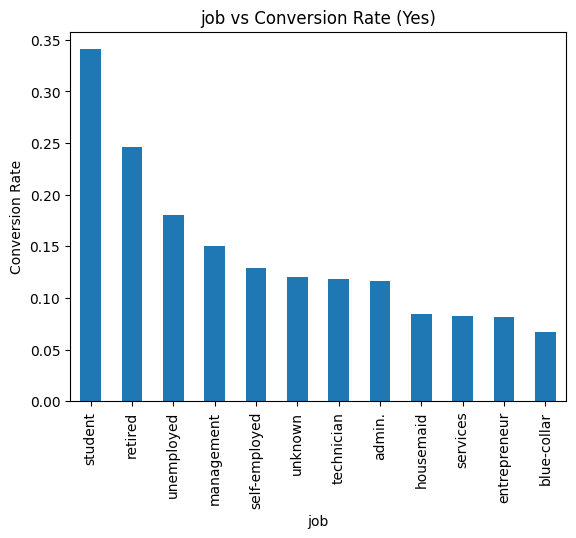
不同職業的轉換率差異更明顯,學生和退休族的轉換率最高,而藍領族群和企業家反而最低,這對後續行銷策略就很有參考價值。
今天把各類別特徵和目標變數的關係都畫出來,也觀察到一些有趣的現象:像是單身族群的轉換率最高、學生和退休族的行銷成功率也很高。
明天我就要開始訓練最基本的 Baseline 模型,看看不用做太多特徵工程的情況下模型能到什麼水準,之後再根據今天的觀察結果來做特徵微調,逐步提升模型表現。


 iThome鐵人賽
iThome鐵人賽